为什么建议少用if语句,不是运行效率
从汇编角度比较 if 和switch 性能差异
絮絮叨叨 : 这个五一就好好的当个技术宅吧,把之前欠的作业给补上,后面争取稳定周更一篇
if 和 switch 性能差异
在写代码的时候肯定会用到不少if和switch语句,除了我们都知道的用法上的差异,性能上有什么差异。
这篇文章尝试从汇编的角度去解决下面的几个问题。
- 影响if和switch性能的差异点在哪,他们有何异同。
- if和switch的差异临界点在那,什么时候if和swtich的性能是一样的?
- 如何选择使用if和swtich。
以下分析运行环境为 centos7 , gcc8.3
if 和 switch 用法区别
if 和 switch 用法的区别导致了他们在运行时效率差异的根本原因。
先看两段代码:
代码一(test_if.c):
#include "constant.h"
int test_if(int num)
{
int result;
if (num == VALUE1)
{
result = num + 5;
}
else if (num == VALUE2)
{
result = num + 9;
}
else if (num == VALUE3)
{
result = num + 12;
}
else if (num == VALUE4)
{
result = num + 15;
}
else if (num == VALUE5)
{
result = num + 31;
}
return result;
}代码二(test_switch.c):
#include "constant.h"
int test_switch(int num)
{
int result = num;
switch (num)
{
case VALUE1:
result = num + 5;
break;
case VALUE2:
result = num + 9;
break;
case VALUE3:
result = num + 12;
break;
case VALUE4:
result = num + 15;
break;
case VALUE5:
result = num + 31;
break;
default:
result = 0;
}
return result;
}其中 VALUE1,VALUE2,VALUE3是在头文件constant.h定义的宏:
#ifndef CONSTANT_H_
#define CONSTANT_H_
#define VALUE1 101
#define VALUE2 103
#define VALUE3 105
#define VALUE4 107
#define VALUE5 111
#endif上面的两段测试代码,完成相同功能:将传入的参数加上一个值后返回。
在if语句的测试代码中,使用if-else对所有条件进行逐一判断,满足条件后执行对应的代码。
而在swtich的测试代码中,直接根据num的值,跳转到对应标签的代码段执行。
if和switch都可以根据不同的输入,选择执行对应的代码,但是用用法上看,if语句需要对条件逐一判断,而switch语句,则不要判断直接可以跳转到对应的代码。
在我的理解中,switch语句有点像一个哈希表,实现整形数字到一个地址空间的映射,在使用时整形数字作为键(key),然后跳转到对应代码的地址(value)去执行。
然而在C语言中不存在map这种数据结构,在CPU的指令中也不存在这样的指令。
if 和 switch 汇编代码分析
在switch语句中,实现了类似哈希表(hash table)的数据结构。
在C语言中并不直接支持哈希表,如果要使用则必须自行设计相关代码。
通过汇编命令gcc -S -O1 test_switch.c -o test_switch.s查看gcc在编译时如何处理switch语句。
上面两段程序对应的汇编代码如下:
test_if.s
test_if:
.LFB0:
.cfi_startproc
movl $106, %eax ;设置返回值寄存器为106
cmpl $101, %edi ;将参数和立即数101比较,相等将ZF标志位置位
je .L1 ;如果ZF置位,则跳转到L1
movl $112, %eax
cmpl $103, %edi
je .L1
movl $117, %eax
cmpl $105, %edi
je .L1
movl $122, %eax
cmpl $107, %edi
je .L1
cmpl $111, %edi
movl $0, %eax
movl $142, %edx
cmove %edx, %eax
.L1: ;返回
retswitch_test.s
test_switch:
.LFB0:
subl $101, %edi ;计算根据参数,计算索引值
cmpl $10, %edi ;索引大于10,则跳转(与下面语句配合使用)
ja .L9 ;如果CF=0 且 ZF=0,跳转到default代码段,
movl %edi, %edi
jmp *.L4(,%rdi,8) ;跳转到索引对应的地址标号
.section .rodata
.align 8
.align 4
.L4: ;地址标号跳转表
.quad .L8
.quad .L9
.quad .L7
.quad .L9
.quad .L6
.quad .L9
.quad .L5
.quad .L9
.quad .L9
.quad .L9
.quad .L3
.text
.L8:
movl $106, %eax ; 将结果放入返回值寄存器
ret ; 返回
.L7:
movl $112, %eax
ret
.L6:
movl $117, %eax
ret
.L5:
movl $122, %eax
ret
.L3:
movl $142, %eax
ret
.L9:
movl $0, %eax
ret注:为了简单汇编代码长度,在编译汇编代码,开启了1级优化,不同等级优化的汇编结果不同。
在test_if对应的汇编代码中,可以很明显的看到程序处理逻辑为:依次判断是否满足条件,满足条件则执行对应代码。
在switch的汇编代码中,可以发现程序逻辑明显不同与if-else语句。
在switch的汇编中,首先将所有case对应的代码开始地址,放到L4标号所对应的连续地址中。
它可以理解为生成了一个常量数组const uint32_t L4[VALUE5-VALUE1]={...};,其数组内容顺序是按照处理case处理后的索引排序。
例如VALUE3对应的值为103,首先生成索引103-100=3,然后L4[3]对应的值就是case 103 所在的代码开始地址。
在switch的汇编中,为了实现直接跳转功能,使用数组实现了一个哈希表,而对应的哈希函数由编译器自动生成,在上面代码中哈希函数为 value = L4[key-100];
实际上这种应该叫跳转表(jump table),而不是哈希表(hash table)。
if 和switch性能差异比较
通过汇编代码的比较可以发现,使用 test_switch.o 的代码大小比 test_if.o 的代码大小要高出不少,test_if.o大小为105字节,而test_swtch.o大小为189字节。
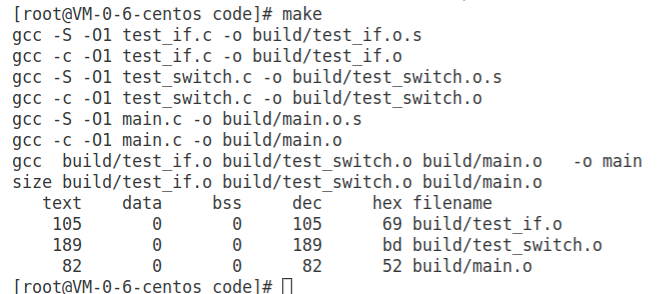
这是鱼和熊掌不可兼得的一个体现,switch 语句减少了判断的时间,但是引进跳转表增加了代码空间,不过在大多数情况下这种代价是划算的。
不过通过对上面的汇编代码分析,需要质疑的是switch语句的效率一直if语句高吗?
在上面的汇编代码中知道,switch实际是使用跳转表实现的,如果各项case值差异很大呢,它还会生成跳转表吗?
我们把之前头文件对应VALUE的值改动后,重新生成汇编代码查看:
#define VALUE1 1
#define VALUE2 10
#define VALUE3 30
#define VALUE4 50
#define VALUE5 111汇编代码:
test_switch:
.LFB0:
.cfi_startproc
cmpl $30, %edi
je .L4
jle .L9
movl $65, %eax
cmpl $50, %edi
je .L1
cmpl $111, %edi
movl $0, %eax
movl $142, %edx
cmove %edx, %eax
ret
.L9:
movl $6, %eax
cmpl $1, %edi
je .L1
cmpl $10, %edi
movl $0, %eax
movl $19, %edx
cmove %edx, %eax
ret
.L4:
movl $42, %eax
.L1:
ret可以发现在cese各项值之间差异很大,switch语句将退化为if结构,和if语句效率无明显差异。
if 和 switch 选择
- 在分支数量小于4时,两者无明显差异,都是使用 cmp-jmp 指令进行处理。
- 在分支数量大于4,且case间跨度较小时,编译器使用跳转表可加快处理时间。
- 在case值跨度比较大时,switch语句退化为cmp-jmp 指令,性能无明显差异。
- 在分支数量比较多跨度比较大,且需要加快处理时间,可自行设计数据结构实现跳转表。